Online platformsAn online platform refers to a digital service that enables interactions between two or more sets of users who are distinct but interdependent and use the service to communicate via the internet. The phrase "online platform" is a broad term used to refer to various internet services such as marketplaces, search engines, social media, etc. In the DSA, online platforms... More largely rely on content moderationReviewing user-generated content to ensure that it complies with a platform’s T&C as well as with legal guidelines. See also: Content Moderator More to remove illegal or harmful content, such as terrorist or child abuse images and videos. Often illegal content that has been detected and removed re-appears, possibly multiple times, as manipulated copies – for example, images with added watermarks, cropped, rotated, edited, etc. Reappearing illegal content can be a significant percentage of illegal content online for many platforms. Hence, automatically and accurately re-detecting manipulated copies of previously removed content can have a significant impact on the quality of a company’s content moderation and on online Trust and Safety. In this blog we discuss the problem of detecting manipulated copies of images, outlining a generic approach while also reviewing some methods used in computer vision.
What is Copy Detection?
Image copy detection involves determining whether a target image is a copy or an altered version of another image in a dataset (the reference images, possibly a large collection of images, for example, those that have been previously detected and removed from a platform). The goal is to identify whether two images originate from the same source or not. Note that this is different from other related computer vision problems, such as instance-level recognition (images of the exact same object taken under different conditions, e.g. from different angles), or category-level recognition—images containing different versions of the same concept (e.g. a red car and a blue car), or image similarity detection where the problem is to detect whether images are different photos of the same instance but for example from different angles or taken under different conditions (Figure 1).

A general pipeline for copy detection
A general pipeline to develop image copy detection methods is shown in Figure 2. All the methods we discuss here only differ in terms of the deployed model to extract features. Below, we explain each of the four steps and review some relevant techniques.

Images Dataset
Online platforms, such as social media, which may receive millions of images each day, have an incentive to automatically detect harmful content that is reposted on their platform. For example, the Facebook AI team hosted a competition to encourage other research teams to tackle this problem, and developed a dataset [3] of transformed images (Figure 3) that are representative of the augmentations that are common on the internet. We use this data below.

Embeddings: Creating Useful Representations

Digital images are made up of pixels. If all the pixel values of a picture, such as the cat in Figure 4, are “flattened out” into a single sequence, we can represent the image as a high-dimensional vector with elements being the pixel values (as indicated in the image above). We can do the same with an entire dataset of reference images as well as any query one. However, using this pixel representation may not facilitate the comparison of similar (e.g., copied and manipulated) images. For example, if one rotates an image (even a little), the pixel vector of the rotated image will be very different from that of the original one. It is therefore practically useful to have a vector (or matrix) representation of images that captures some visual relationship between images spatially—so that “similar” images are closer together, where “similar” in our case means “produced from the same original image/source”. Such an arrangement, called an embedding, allows us to translate a problem that humans solve visually into a mathematical problem that can be solved, for example, by computing distances between vectors (which are the representations of the images).
We, therefore, need a method of producing useful embeddings, that is to say, a way (i.e, a function) of mapping raw-pixel vectors to vectors so that similar – according to the copy-detection definition of similarity in our case – images are close. In this project, we explore two well-known approaches to do this (See Figure 5). One in which images are described in terms of a set of small, characteristic local visual features and another that uses convolutional neural networks (CNN) to learn an embedding:
- Local Descriptor Based Models (a more classical approach): Local feature detectors generate vectors for numerous local regions, which can then be compacted into an embedding.
- Deep Learning Based Models (a more recent approach): These models leverage trained Deep Learning models to extract embeddings. For example, one can take the output of a layer of a CNN as the embedding to use as a representation of an image.
Local Descriptor Based Models
These models consist of two main steps: Local descriptor extraction and encoding.
Local features, or local descriptors, refer to patterns or distinct structures found in an image, such as corners, edges, or small image patches. They are usually associated with an image patch that differs from its immediate surroundings by texture, color, or intensity. What a feature represents does not matter, just that it is distinct from its surroundings.
Local descriptor extraction – Scale Invariant Feature Transform (SIFT)
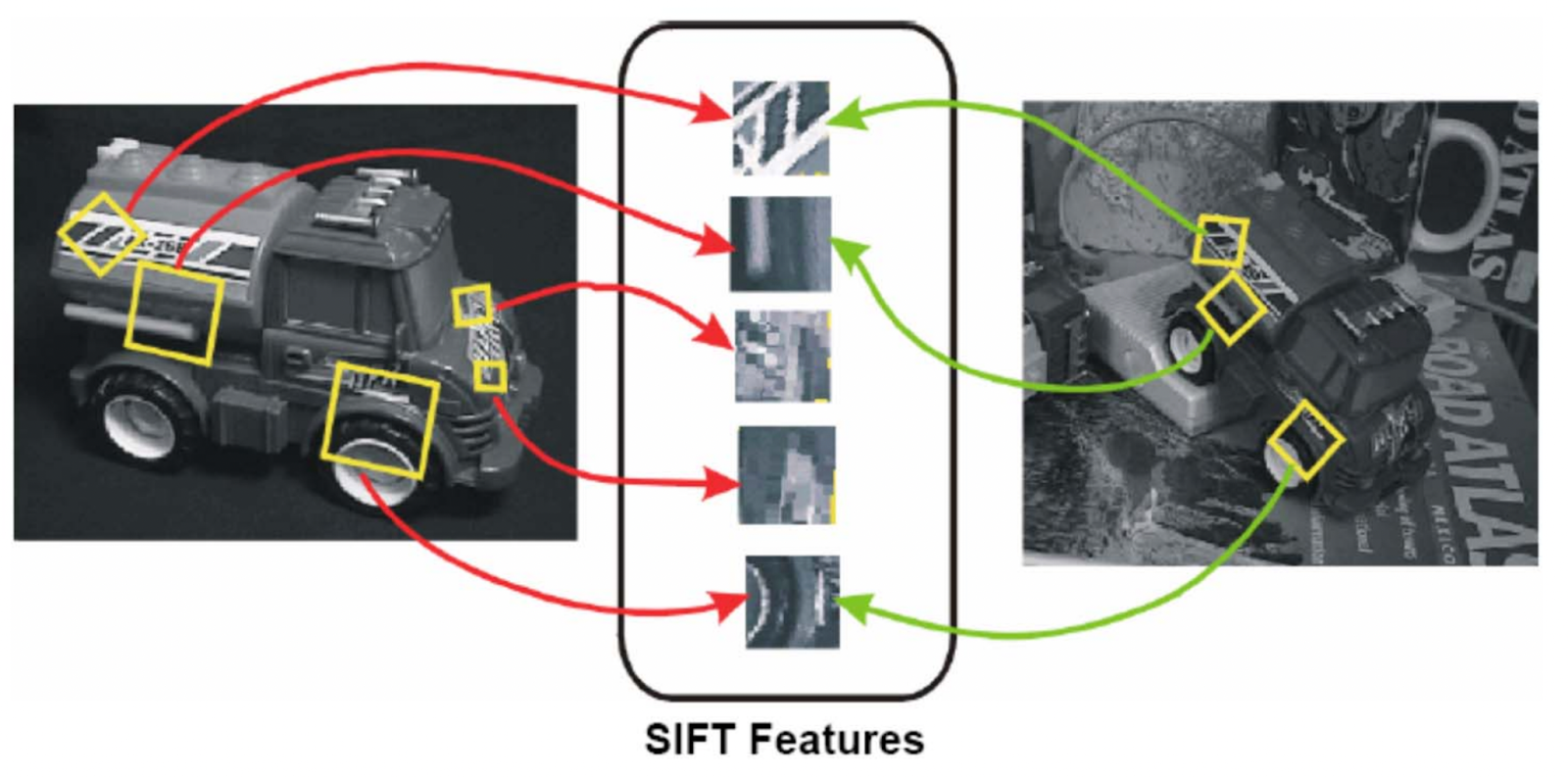
Scale Invariant Feature Transform (SIFT) is an algorithm that works by detecting the most significant regions (i.e. key points) in an image and describing them using vectors called key points descriptors. The descriptors are invariant to a variety of visual transformations (e.g. translation, scaling, and rotation), so they can be used to identify images that are different perspectives of the same object or are certain manipulations (e.g., rotations or translations) of the same image. SIFT describes each keypoint using a descriptor (a vector) that captures the location, scale, and orientation of the keypoint, leading to a representation of each image keypoint using 128 numbers (so each keypoint is a 128-dimensional vector). To achieve this, SIFT is mainly composed of the following stages [7]:
- Scale invariant Key Points Identification: Accurately locating key points in an image.
- Orientation Assignment: Assigning a principal orientation to each key point of the image.
- Key Points description creation: Describing the key points using a high dimensional vector (of size 128).
Each of these stages consists of a number of steps. Some useful tutorials about how these stages work can be found in these videos. For example, how does one even identify “interesting key points” in an image? This is what the scale invariant key points identification stage does (details about how key points can be identified can be found here). Briefly, the method can be summarized as follows. A useful image keypoint [13] is a region that is visually distinct from its surroundings but relatively consistent within itself. Such a region, a “blob”, is distinguishable because it’s typically bounded by edges, i.e. sharp changes in brightness or color – see Figure 7.

A method to find these key points is to apply the second derivative of the gaussian function, the Laplacian of Gaussian (LoG) (it looks like an upside-down Mexican hat), as a filter to the image. The output created by filteringFiltering, in the context of content moderation, is a (typically automated) process that involves the automatic removal, downranking, or disabling of content that meets specific criteria. More an image with a LoG will have local extrema wherever the image has a blob – and generally some changes (e.g., color, texture, etc). Additionally, we apply the LoG filter to the image using different scales of the filter because some regions that don’t look like blobs at one scale can be correctly identified at another (hence the scale invariance characteristic of SIFT features). We can therefore find all the blobs in an image by determining the local extrema of the image after applying the LoG filter at multiple scales/image resolutions. Achieving scale invariance is an important capability of SIFT type methods. After a collection of potential key points has been identified, a few checks are applied to eliminate unnecessary outliers. Orientation-related information about each key point is then found during the orientation assignment stage. This information is then used to create eventually a descriptor (vector) for each keypoint of size 128 that is scale, translation, and rotation invariant (see how this is done in this video).
Encoding: Vector of Locally Aggregated Descriptors (VLAD) based Embedding
One drawback of the use of key points is that a single image is represented by a large number (typically thousands) of them. If we want to perform image matching using SIFT-generated features, all of these key points must be individually compared between a query image and all images in a dataset. Instead, the search process can be optimized by defining only a few, say k, “prototypical” key points (we call this set of key points a “codebook” and sometimes call the “prototypical” key points visual words) that have been identified across all images in our database, and then describe each of the database images as well as the query ones using only these few visual words [10][12]. Think of the codebook as a common library of visual words that are prominent across all images in the database, such as patterns like edges and corners. For example, let’s say we start from a total of 9000 visual words across all images in our database (each being a vector of size 128 if we use SIFT), 800 of them representing horizontal edges, 600 representing vertical edges, etc. While building the codebook, the clustering algorithm can put all these horizontal edges in one cluster, and then the most typical key point vector of this class will be considered as its center (e.g., the most typical horizontal edge, etc.) which will be used for the codebook.
A codebook can be created using, for example, unsupervised learning techniques such as k-means clustering, where we cluster all key points found across all images in the database. The size k (number of clusters) of the codebook C = {c1, … , ck} can be determined empirically (for example in our case we considered values ranging from k=16 to k=256). The k elements {c1, … , ck} of the codebook are the centers of the clusters found. More information can be found in this video.
Once a codebook C is created, one can then represent each image using this codebook. One method to do so, that we use here, is VLAD (vector of locally aggregated descriptors) [10][12]. With this method, we represent each image using a vector U=[u1T,u2T,…,ukT] , where ui= NN(xj)=ci xj -ci . Here j represents the j-th key point (say, found using SIFT) of the image whose closet element in the codebook is ci (i=1,…,k), namely ci = NN( xj) where NN stands for nearest neighbor. Essentially, given the key points of an image we: first assign each key point of the image to the visual word i of the codebook that is the closest to that keypoint; then take the distance of the keypoint from that visual word, and sum up these distances for all key points “assigned” to that visual word i. This is what ui (for visual word i) is. Note that all ui (i=1,…,k) have the same size which is equal to the size of the initial local features/key points used (e.g., 128 dimensional if we use SIFT). Therefore, the dimensionality of the whole embedding U describing any image is fixed – and in the case of SIFT it is (128 x k).
Deep Learning Based Models
In recent years, the popularity of SIFT-based models has been often overtaken by CNN models, which have been shown to outperform local feature detectors in many vision tasks. While there are many CNN models, we used embeddings from two main groups of models, one that is based on supervised learning (e.g., image classification) and one on self-supervised learning:
- General Visual Representation Learning models are trained in a supervised manner on large datasets, such as ImageNet, to perform image classification (e.g. is this an image of a dog or a cat?). The representations that are learned can sometimes be used to effectively solve different tasks, other than, say, image classification. For example, the BiT-ResNet family model [8] that we used below is known to provide excellent performance across a wide variety of different tasks. Note however that this model is not trained specifically for the copy detection problem we are interested in.
- Self-Supervised Contrastive Learning models are well suited to image copy detection because they produce similar (i.e. well clustered in the Embedding space) features for images that come from the same image source, and different representations across images otherwise. This is accomplished by generating augmented versions of images in a dataset, then training a CNN to minimize the distance between representations of sibling images while maximizing the distance of these sibling images with respect to all other images.
(SSCD) A Self-Supervised Descriptor for Image Copy Detection

One of the state-of-art Self-Supervised Contrastive Learning models for image copy detection—Self-Supervised Descriptor for Image Copy Detection (SSCD)—was developed by the Facebook AI team to solve the problem specified in their 2021 Image Similarity Competition (Figure 8). While the method has multiple components (we do not use them all in the experiments below), we focus on two key ones: contrastive learning using a method called SimCLR, and entropy regularization. We describe these briefly next.
Contrastive Learning using SimCLR
In Contrastive Learning we train a neural network with pairs of data (e.g., images) that may or may not be instances of the same object (e.g., source image). Two data points that are instances of the same object are called a positive pair, else they are a negative pair. In the embedding space produced by the network, we would like the vectors of positive pairs to be close together while vectors of negative pairs remain far apart (as in Figure 9).

The loss function of a neural network is partly determining how the network is trained as well as the embeddings one can generate from it. Therefore, selecting a loss function that achieves the goal above is key. A contrastive loss function that achieves the separation we’re looking for is

averaged across all positive pairs (i,j), where si,j and si,k are the cosine similarity of positive and negative pairs that include image i, respectively. This loss is minimized when the similarity of a positive pair is high compared to the sum of all negative pair similarities.
SimCLR (Figure 10) is a method for computing contrastive learning representations in a self-supervised manner, that is, without any pre-labeled data. As it is self-supervised, we first generate pairs of data to use with the contrastive loss. Specifically, for each image that is available during training, two copies are made and augmented to produce two views of the same image, refer to Figure 11 for example. We are then generating pairs of these augmented views across all images. If a pair is of two views of the same original image, it is labeled as a positive pair, else it is a negative pair. The pairs of views can then be used to train a CNN using the contrastive loss above.
However, the developers of SimCLR noted that reducing the dimensionality of the representations during training using a standard neural network (a multilayered perceptron, MLP) in addition to a CNN improved the final performance. SimCLR, therefore, trains a combination of a CNN and an MLP using the generated pairs and the contrastive loss above as indicated in the figure below.


Entropy Regularization
For SSCD, an additional “regularization term” is added to the loss function above (when training the CNN and the MLP) to add an additional “constraint” to the embedding space layout. Namely, this term is added in the loss function optimized during training:

where zi, zj are representations of images i and j, and Pi is the set of all positive pairs that include image i.In other words, for each image we also maximize the distance of this image from all other images with which it forms a negative pair. Impact and tradeoff using entropy Regularization are described in detail in this paper.
Candidate Image Retrieval
One of the challenges of the image copy detection problem is that we want to retrieve similar images on a large scale, potentially among millions of images. Accelerating the search involves indexing, which is often performed by pre-processing the database (e.g., splitting it into clusters or organizing it in a tree structure) to organize it better for efficient search. For all our tests, we use a default method by the FAISS library, which does not involve any pre-processing of the reference features set – storage in the database is simply sequential, and search in the database is likewise.
For all methods, we perform the K-Nearest-neighbor search based on the FAISS library faiss.knn [9], with the similarity between two images evaluated using the Euclidean distance between the database images (their feature representation) to the query image (its feature representation). Other distance metrics can also be used.
Post Processing
Other operations could be applied within the pipeline after embeddings are created, for reasons of efficiency and consistency. For example:
PCA Whitening is a processing step for Embeddings that makes them less redundant. Dimensions of Embeddings can be highly correlated, and whitening through the use of PCA reduces this degree of correlation.
Similarity Normalization is used to compute similarity scores during retrieval. Mathematically, it subtracts from the similarity score between a query image q and a reference image r the average similarity between the query and multiple images in the dataset. This operation may improve performance but adds operational complexity.
We do not discuss these operations as we found they have little impact during the experiments.
Experiment Setup
Dataset
In the experiment below, we use a subset of the DISC 2021 dataset [6] from Facebook’s Image Similarity Competition. For simplicity, we took 1500 original images as the Reference dataset and 1000 transformed images as the Query dataset. Among the Query dataset, there are 500 in-domain query images, i.e. there exists a corresponding original in the reference dataset, and 500 out-of-domain query images, i.e. there is no original image in the reference dataset. We worked with pre-trained models to get the embeddings.
Experiments for each method can be divided into 2 stages.
- During the computing stage, we deploy a corresponding Local Detector Based Model or Deep Learning Based Model to extract features of all images from the Reference Dataset. We then store all these features using a simple sequential indexing strategy, which will be used in the next stage.
- During the evaluation stage, we extract features of all images from the Query Dataset. We then search in the stored features of the Reference Dataset and retrieve possible original images. Search and Retrieval works as follows: given a query image, the copy detection method computes the similarity score between the query image feature and each of the stored Reference image features. If the score is higher than a threshold, then this reference image is regarded as a candidate, i.e. a possible original image; else, this reference image is highly probably not the original image. After traversing all reference image features, if there are no candidate images, the copy detection method returns nothing; else it returns a list of at most 10 (if there are) candidate reference images, ranked by the similarity score.
Method Evaluation
We define:
TP (True Positive): We use an in-domain query image, the search returns candidate images from the database, and top 10 candidate images that the method returns contain the correct original image.
FN (False Negative): We use an in-domain query image and the method returns nothing or returns top 10 candidate images that are only irrelevant images.
TN (True Negative): We use an out-of-domain query image and the method returns nothing
FP (False Positive): We use an out-of-domain query image and method returns something (top 10 or less)
We calculate the following criteria:
Recall@10 = TP/(TP+ FN): this measures the proportion of actual positives that was found. It indicates how well the method finds previously seen images.
Precision@10 = TP/(TP+ FP): this measures how reliable the predictions are. This means the method suggests (1-Precision@10) of the time “copies” of an image even if that image was never seen before.
Methods Tested
SIFT-VLAD model
This is a Local Detector Based Model. We first extract SIFT descriptors for all images, and then use Vlad to create the final 128 x K – dimensional embeddings for each image
General visual representation model
Directly deploy the BiT-M R50x1 model to extract features. This pre-trained model implemented ResNet-50, and it is trained to perform multi-label classification on ImageNet-21k, a dataset with 14 million images labeled with 21,843 classes. The embeddings are 2048-dimensional.
SSCD model
We resize all images to square with an edge size of 480 pixels, and then directly deploy the sscd_disc_mixup model. The embeddings are 512-dimensional.
DENA model
We resize all images to square with an edge size of 512 pixels, and then directly deploy the DeNA model (details can be found in [5]). The embeddings are 512-dimensional.
Results and Observations
Performances of the different methods tested are shown in the table below. Overall the two deep learning based representations (SSCD and DENA), that are more specialized for the copy detection problem, perform the best – and similar to each other. Instead, a system based on a general visual representation shows very poor performance in this case, while the SIFT based approach is in between.
| Method | Threshold | Recall | Precision |
| General visual representation | 9500 | 7.40% | 7.35% |
| 9500 | 11.20% | 10.81% | |
| SIFT-VLAD | 0.3 | 35.00% | 36.02% |
| 0.1 | 48.00% | 32.43% | |
| SSCD | 0.25 | 67.40% | 99.70% |
| 0.20 | 73.60% | 92.23% | |
| DENA | 0.40 | 73.00% | 98.38% |
| 0.22 | 71.00% | 97.26% |
In this blog, we described a general pipeline for developing a system to detect similar images in a database. We have identified key components and discussed commonly used options for them. We tested variations – performances are shown in the table above.
A key message is that, perhaps not surprisingly, the choice of features to represent images is the most significant one. Deep learning-based representations are state-of-the-art, but even in this case, one needs to use representations that are matching the specific task at hand. For example, a general visual representation doesn’t necessarily work for copy detection, the main reason perhaps being that the network is trained on image classification tasks, thus the output embeddings of images probably represent image categories’ information without capturing image manipulations. On the contrary, the main idea of self-supervised contrastive learning is to project images generated (via manipulations) from the same original one onto similar embeddings – and others onto very different ones. Finally, local descriptor-based methods such as SIFT-VLAD have relatively poor performance in this specific case and dataset (although they are known to work well in many applications): they probably cannot capture all the types of manipulations (e.g.,beyond rotation and scaling) one can do on images.
In addition, while there are multiple image post-processing steps explored in the literature, we found these can potentially add only a little extra performance in this case. For example, we explored (not reported here) Geometric verification using RANSAC [15] which only slightly improved performance, but as a result, using it we need to sacrifice computational time. Of course, future research may improve the impact of such steps.
References
[1] The Image Similarity Challenge and data set for detecting image manipulation
[2] SIFT Meets CNN: A Decade Survey of Instance Retrieval
https://arxiv.org/abs/1608.01807
[3] The 2021 Image Similarity Dataset and Challenge
https://arxiv.org/abs/2106.09672
[4] A Self-Supervised Descriptor for Image Copy Detection (SSCD)
https://github.com/facebookresearch/sscd-copy-detection
[5] Contrastive Learning with Large Memory Bank and Negative Embedding Subtraction for Accurate Copy Detection
https://arxiv.org/abs/2112.04323
[6] DISC2021 dataset
https://sites.google.com/view/isc2021/dataset
[7] Object Recognition from Local Scale-Invariant Features
https://www.cs.ubc.ca/~lowe/papers/iccv99.pdf
[8] BiT-ResNet
https://github.com/google-research/big_transfer
[9] FAISS library
https://github.com/facebookresearch/faiss
[10] Aggregating local descriptors into a compact image representation
[11] Contrastive Loss Explained
https://towardsdatascience.com/contrastive-loss-explaned-159f2d4a87ec#:~:text=Contrastive loss takes the output,the distance to negative examples.
[12] From Points to Images: Bag-of-Words and VLAD Representations
[13] What is an interest point? SIFT Detector
[14] Introduction to SIFT( Scale Invariant Feature Transform)
https://medium.com/data-breach/introduction-to-sift-scale-invariant-feature-transform-65d7f3a72d40
[15] Geometric Verification with RANSAC

